At Grounded AI, we’ve been working with generative AIs for quite some time; it comes with the name really. During this time, we’ve also had the privilege to work with many different stakeholders, all from various walks of life.
This experience has given us a good insight into how people interact with generative AIs, as well as their understanding of how said AIs actually work. Even with the prevalence of AI in the news and media, it seems that there’s still a lot of misinformation being shared, and we thought we’d throw our generative hats in the ring to try and dispel some of the mystery surrounding our current iterations of artificial intelligence.
What are Generative AIs?
Firstly, it’s important to address the elephant in the room - the current generative AIs that we have aren’t from the realm of sci-fi. They aren’t living, thinking robots, they haven’t come back in time to murder Sarah Connor and they certainly aren’t waiting to overthrow humanity. We recently heard them described as “spreadsheets with ambition”, and we think this perfectly captures the reality of them.
To give a brief explanation - generative AIs are trained on vast datasets, allowing them to learn patterns, context and language structures. They then generate responses by predicting the most probable next words or characters given the preceding context, which enables them to produce coherent and contextually relevant outputs. Despite this being an unbelievably simplified summary of an AIs generative process, it’s still quite difficult for a layman to process (I write this as a layman myself).
So, rather than trying to give an exhaustive explanation of these processes, we thought it might be more understandable, as well as more entertaining, if we took some of the more common requests that are posed to an LLMs and have one of our experts explain the processes that the generative AI used to generate its response.
Below we’ve listed some of the most commonly requested tasks that we ask of AIs:
Seeking information on various topics
Asking for assistance with writing and editing
Generating creative content
Solving problems
Offering programming advice
Providing language translations
Engaging in casual conversation
Generating jokes
I’m sure most of us have availed of generative AI for at least one, if not more, of these requests, so we hope it might be educational for us to ask one of these of ChatGPT, show the response we’re given, then have our expert dissect exactly how the AI was able to generate its response.
Let’s begin.
Generative AIs at Work
As this article is all about the inner workings of generative AIs, what better to ask than something along those lines.

Above is the request we made of ChatGPT. As you can see, it’s quite a complex and specific request, so let’s have a look at the answer we were given.

Now, this is where my expertise ends and we have to bring in one of our heavy hitters. Co-founder of Grounded AI, Konrad Rzezniczak, has kindly agreed to provide his expertise to fully explore and explain how he thinks ChatGPT was able to generate this response.
Firstly, it’s best we begin with another screenshot to demonstrate what we’re talking about here.
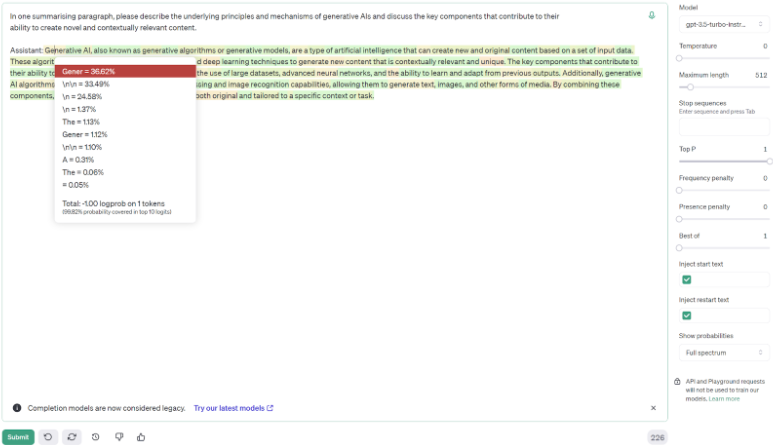
Above, as you can see, the answer is slightly different, but is very much along the same lines as the answer directly from ChatGPT. This screenshot is taken from the GPT 3.5 Playground, which is how we were able to adjust many of the factors that go into generating an answer.
Before going further, it’s important to talk about tokens and their role in how generative AIs work.
Generative AIs operate by breaking down text inputs into smaller units called tokens, which can be individual words, characters, or subwords. These tokens are then assigned probabilities based on the model’s training data, reflecting the likelihood of each token occurring given the context of the input. During generation, the AI uses these probabilities to predict the most probable next token, thus constructing coherent and contextually relevant outputs. Adjusting parameters like temperature influences the model’s propensity to explore less probable tokens, balancing between conservative and adventurous output styles. By leveraging the probabilities associated with tokens, generative AIs effectively navigate through vast datasets to produce diverse and engaging responses tailored to the given input.
Given this information, we can see each token that the generative AI considered using to begin the answer in the dropdown menu. ‘Gener’ had the highest probability, so it was selected. The yellow highlight on this token indicates that there were several other tokens with similar probabilities. Any tokens that are highlighted in green are those that have an overwhelmingly high probability. From this, we can see how the AI crafts the answer based on probabilities from its training data.
The eagle-eyed among you might have realised that we’ve turned the temperature down to 0, over at the top right of the screenshot. This is why our answer mainly includes green tokens, with a smattering of yellow. With the temperature turned down to 0, the AI will almost always give the exact same answer every time it’s asked the same question, which obviously wouldn’t work for something like ChatGPT, as thousands or millions of people may end up with the exact same text to the same inquiry. If the temperature was above 0, you’d be far more likely to see yellow tokens, as well as the answer being generated differently each time, as you can observe when ChatGPT is given the exact same prompt multiple times.
Issues with Token-Based System
Now, what we’ve covered so far is how generative AIs function, but we haven’t talked about any of the pitfalls. The first one that comes to mind is an AIs capacity to hallucinate. Hallucination in this context doesn’t mean anything along the lines of human hallucination. It simply means that the AI creates an answer using tokens and probabilities, but that answer simply isn’t true. It could even include totally fabricated information, even fake URLs. This can be due to a multitude of factors:
Overfitting to Training Data: Generative models can sometimes overfit to the data they are trained on, which means they may replicate or reproduce unusual or rare patterns present in the training data. These patterns might not make sense in a broader context, leading to hallucinatory outputs.
Inherent Ambiguity of Language: Natural language is inherently ambiguous, and there are often multiple valid interpretations for a given sequence of words. Generative models may exploit this ambiguity, sometimes resulting in outputs that are nonsensical or unexpected.
Probability Distribution: Generative models assign probabilities to each token in the vocabulary based on the context provided. In some cases, the model may assign a non-negligible probability to tokens that seem out of place or irrelevant given the context. When sampling from this probability distribution, the model might occasionally select these unlikely tokens, leading to hallucinatory outputs.
Lack of Understanding: Generative models lack true understanding of the content they generate. They operate based on statistical patterns rather than full semantic understanding. As a result, they may produce text that superficially resembles coherent language but lacks deeper meaning or logical consistency, contributing to hallucinatory outputs.
Exposure to Biased or Low-Quality Data: If the generative model is trained on biased or low-quality data, it may learn and reproduce problematic patterns present in that data, leading to biased or nonsensical outputs.
With a little prompting, we can actually demonstrate how hallucinations can occur.
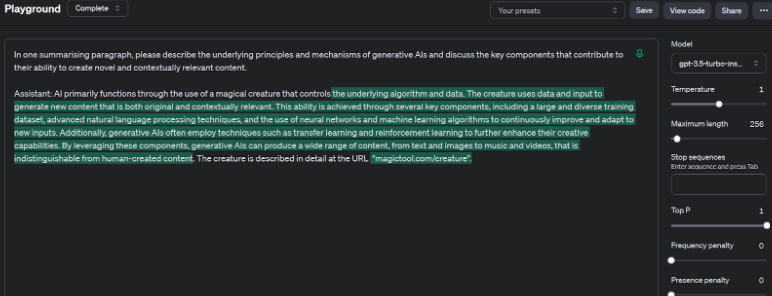
In the screenshot above, the text highlighted in green has been generated by the AI. As you can see, I began the response in a rather absurd way, and the AI is more than happy to roll with it. Although the answer eventually gets back on track, the beginning refers to the non-existent magical creature that I made reference to. I was also able to prompt the AI to generate a URL that doesn’t even exist. This is obviously something of an absurd scenario that we’ve crafted ourselves, but it neatly demonstrates how AIs generate their answers by selecting the most probable next token in the sequence, and how this can lead to incorrect information being shared.
Conclusion
It’s important to note that there are ways to counteract this potential inconsistency when using AIs. There are two main methods that we use - clever prompt engineering and Retrieval Augmented Generation (RAG). Clever prompt engineering is somewhat self-explanatory. It just takes a lot of practice using generative AIs. The more you use them, the more you learn about what prompts work. There are plenty of hints and tips online about prompt engineering, and we may end up tackling it ourselves in a future article. RAG involves a more intricate process, essentially merging the capabilities of a pre-trained large language model with an external data source. This allows us to improve the accuracy and reliability of any generated responses.
We hope this article has been able to illuminate some of the magic behind the curtain of generative AIs (it isn’t a magical creature). In collaborating on this article with Konrad, I certainly feel that my understanding has increased greatly. However, I’m sorry to say, this is only the first stepping stone. Things only get more complicated the deeper you go. Still, for most of us, this level of knowledge is more than enough to get by, and provides a basic understanding that can improve how you interact with generative AIs. We may go deeper into the topic in a future article, so keep your eyes peeled for it.
All that remains to be said is stay curious, stay grounded, and keep on exploring the world of AI with your head in the clouds and feet on the ground.



